Question: How many bits used by computer to store one character?
Answer:
The number of bits used by a computer to store one character depends on the character encoding scheme being used. The most commonly used character encoding scheme is ASCII (American Standard Code for Information Interchange), which uses 7 bits to represent each character. However, ASCII only supports a limited set of characters, primarily consisting of basic Latin letters, numerals, punctuation marks, and control characters.
With the advent of more comprehensive character sets and internationalization, other encoding schemes like UTF-8 have become prevalent. UTF-8 is a variable-length character encoding that uses 8 bits (1 byte) for common ASCII characters and expands to multiple bytes for characters outside the ASCII range. UTF-8 can represent a vast range of characters from different scripts and languages.
Therefore, in modern computing systems, the most common answer to the question of how many bits are used to store one character would be 8 bits (1 byte) when considering UTF-8 encoding. However, for legacy systems or when dealing with ASCII-only characters, it would be 7 bits. It's important to note that there are other character encoding schemes, such as UTF-16 or UTF-32, that use different bit representations depending on the requirements of the specific encoding.
MCQ: How many bits used by computer to store one character?
Explanation:
The number of bits used by a computer to store one character depends on the character encoding scheme being used. The most commonly used character encoding scheme is ASCII (American Standard Code for Information Interchange), which uses 7 bits to represent each character. However, ASCII only supports a limited set of characters, primarily consisting of basic Latin letters, numerals, punctuation marks, and control characters.
With the advent of more comprehensive character sets and internationalization, other encoding schemes like UTF-8 have become prevalent. UTF-8 is a variable-length character encoding that uses 8 bits (1 byte) for common ASCII characters and expands to multiple bytes for characters outside the ASCII range. UTF-8 can represent a vast range of characters from different scripts and languages.
Therefore, in modern computing systems, the most common answer to the question of how many bits are used to store one character would be 8 bits (1 byte) when considering UTF-8 encoding. However, for legacy systems or when dealing with ASCII-only characters, it would be 7 bits. It's important to note that there are other character encoding schemes, such as UTF-16 or UTF-32, that use different bit representations depending on the requirements of the specific encoding.
Discuss a Question
Related Questions
- 1. SMPS stands for and Explain in detail
- 2. By using which of the functionality temporary files of the computer can be removed?
- 3. When creating new folder what is default name given by the computer?
- 4. Which toolbar is used to change the font and font size in MS WORD?
- 5. What is Outlook express?
- 6. Who is working as link between Hardware and software?
- 7. Which function is used for finding the square root of any number in MS EXCEL?
- 8. How many total Rows are there in MS EXCEL?
- 9. The process of taking the mouse at desired place is known as
- 10. Horizontal line seen at the bottom of MS WORD is known as
You may be interested in:
Computer Basics MCQsRecently Added Articles

Features to Look for While Choosing the Best Automation Tool
Last updated on: July 15, 2026Posted by: ExamRadar
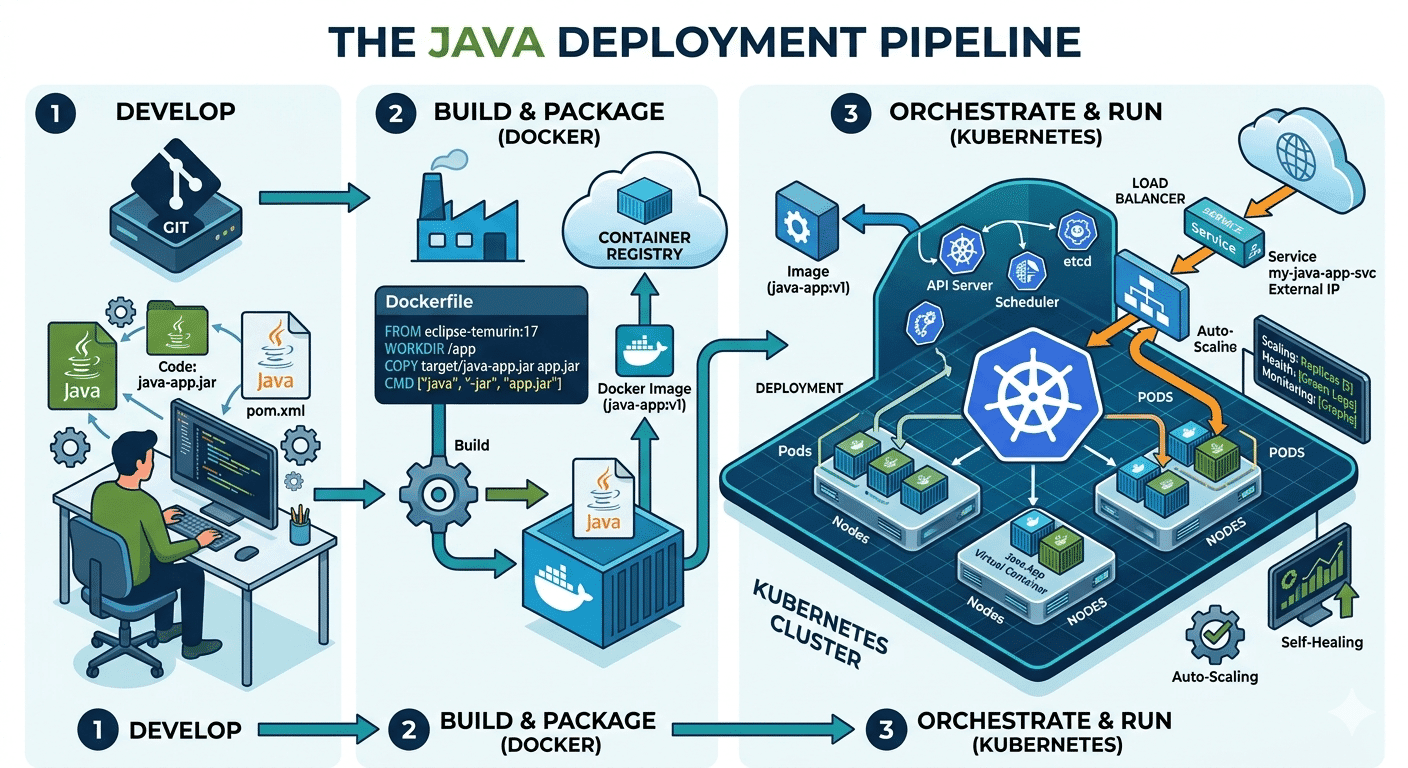
How Do Java Development Teams Use Docker and Kubernetes to Deploy Applications?
Last updated on: April 24, 2026Posted by: ExamRadar

AI vs Machine Learning: Key Differences Every Professional Should Know
Last updated on: February 13, 2026Posted by: ExamRadar

Office Cleaning Services That Elevate Sydney Offices
Last updated on: February 11, 2026Posted by: ExamRadar

What You Actually Learn About Exam Patterns From RBI Grade B Previous Year Papers?
Last updated on: February 9, 2026Posted by: ExamRadar

Mental Health Support That’s Closer Than You Think
Last updated on: January 7, 2026Posted by: ExamRadar

Transform Your Home’s Exterior with Columbus roofing company
Last updated on: November 27, 2025Posted by: ExamRadar
