Operating System – file implementation Long Questions Answers
 Here in this section of Operating System Long Questions and Answers,We have listed out some of the important Long Questions with Answers on File implementation which will help students to answer it correctly in their University Written Exam.
Here in this section of Operating System Long Questions and Answers,We have listed out some of the important Long Questions with Answers on File implementation which will help students to answer it correctly in their University Written Exam.Lists of Long Descriptive type Questions that may be asked in Written Exams.
- (1) Give different types of file system in brief. OR Explain different types of file implementation.
Question-1Give different types of file system in brief. OR Explain different types of file implementation.
Probably the most important issue in implementing file storage is keeping track of which blocks go with which file. Various methods to implement files are listed below,
- Contiguous Allocation
- Linked List Allocation
- Linked List Allocation Using A Table In Memory
- I-nodes
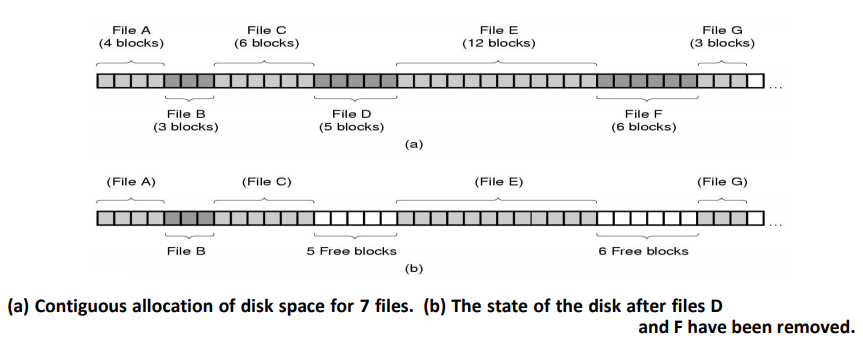
Contiguous Allocation
The simplest allocation scheme is to store each file as a contiguous run of disk block.
We see an example of contiguous storage allocation in fig. 7-5.
Here the first 40 disk blocks are shown, starting with block 0 on the left. Initially, the disk was empty.
Advantages
- First it is simple to implement because keeping track of where a file’s blocks are is reduced to remembering two numbers: The disk address of the first block and the number of blocks in the file.
- Second, the read performance is excellent because the entire file can be read from the disk in a single operation. Only one seek is needed (to the first block), so data comes in at the full bandwidth of the disk.
- Thus contiguous allocation is simple to implement and has high performance.
Drawbacks
- Over the course of time, the disk becomes fragmented.
- Initially, fragmentation is not a problem, since each new file can be written at the end of the disk, following the previous one.
- However, eventually the disk will fill up and it will become necessary to either compact the disk, which is expensive, or to reuse the free space in the holes.
- Reusing the space requires maintaining a list of hole.
- However, when a new file is to be created, it is necessary to know its final size in order to choose a hole of the correct size to place it in.
There is one situation in which continuous allocation is feasible and in fact, widely used: on CD-ROMs. Here all the file sizes are known in advance and will never change during use of CD-ROM file system.

Linked List Allocation
Another method for storing files is to keep each one as a linked list of the disk blocks, as shown in fig. above.
The first word of each block is used as a pointer to the next one. The rest of the block is for data.
Unlike contiguous allocation, every disk block can be used in this method. No space is lost to disk fragmentation.
It is sufficient for a directory entry to store only disk address of the first block, rest can be found starting there.
Drawbacks
Although reading a file sequentially is straightforward, random access is extremely slow. To get to block n, the operating system has to start at the beginning and read the n-1 blocks prior to it, one at a time.
The amount of data storage in a block is no longer a power of two because the pointer takes up a few bytes. While having an unusual size is less efficient because many programs read and write in blocks whose size is a power of two.
With the first few bytes of each block occupied to a pointer to the next block, reads of the full block size require acquiring and concatenating information from two disk blocks, which generates extra overhead due to the copying.
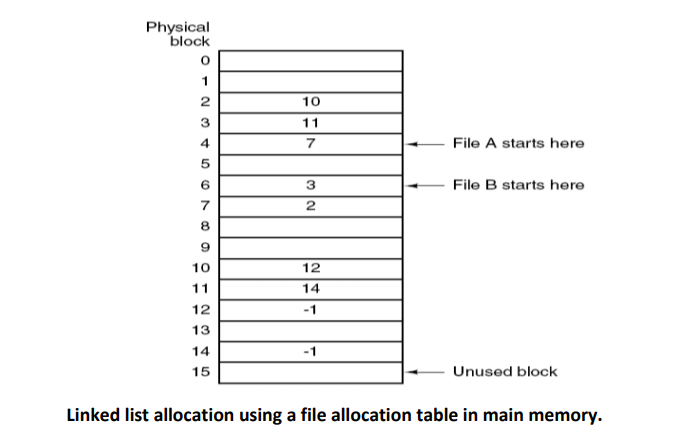
Linked List Allocation Using a Table in Memory / FAT (File Allocation Table)
- Both disadvantage of the linked list allocation can be eliminated by taking the pointer word from each disk block and putting it in a table in memory.
- Figure below shows what the table looks like; in example we have two files.
- File A uses disk blocks 4, 7, 2, 10, and 12 in that order, and file B uses disk blocks 6, 3,11, and 14 in that order.
- The same can be done starting with block 6. Both chains are terminated with a special marker (eg. -1) that is not a valid block number. Such a table in main memory is calleda FAT (File Allocation Table).
- Using this organization, the entire block is available for the data.
- The primary disadvantage of this method is that the entire table must be in memory allthe time to make it work.
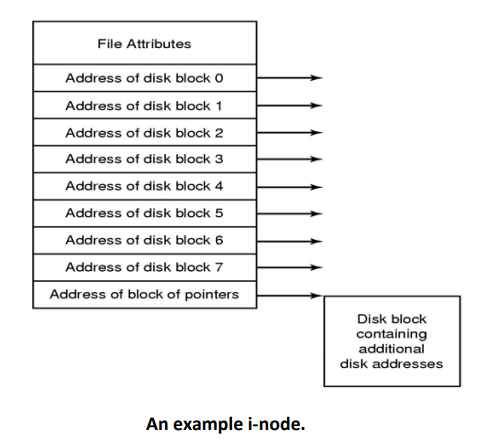
I-nodes
- A method for keeping track of which blocks belong to which file is to associate with each file a data structure called an i-node (index-node), which lists the attributes and disk addresses of the file’s blocks.
- A simple example is given in figure below.
- Given the i-node, it is then possible to find all the blocks of the file.
- The big advantage of this scheme over linked files using an in-memory table is that inode need only be in memory when the corresponding file is open.
- If each i-node occupies n bytes and a maximum of k files may be open at once, the total memory occupied by the array holding the i-nodes for the open files is only kn bytes. Only this much space needs to be reserved in advance.
- One problem with i-nodes is that if each one has room for a fixed number of disk addresses, what happens when a file grows beyond this limit?
- One solution is to reserve the last disk address not for a data block, but instead for the address of a block containing more disk block addresses, as shown in Figure below.